
libellules.ch devient libellules.net
Par Krigou Schnider le jeudi 25 novembre 2021, 14:29 - Actualités - Lien permanent
libellules.ch a vécu ! Un graphisme modernisé, une structure dynamique font évoluer libellules.ch vers libellules.net.
Veuillez mettre à jour vos signets. Désormais, c'est sur libellules.net que cela se passe. Utilisez aussi le nouveau forum pour poser vos questions et pour les problèmes de désinfection !
ATTENTION ! Les anciens avatars, mots de passe, ne sont plus valables pour le nouveau site. Une nouvelle inscription est nécessaire, l'hébergement ne s'effectuant plus sur la même structure.
Merci d'avance pour votre compréhension. Krigou
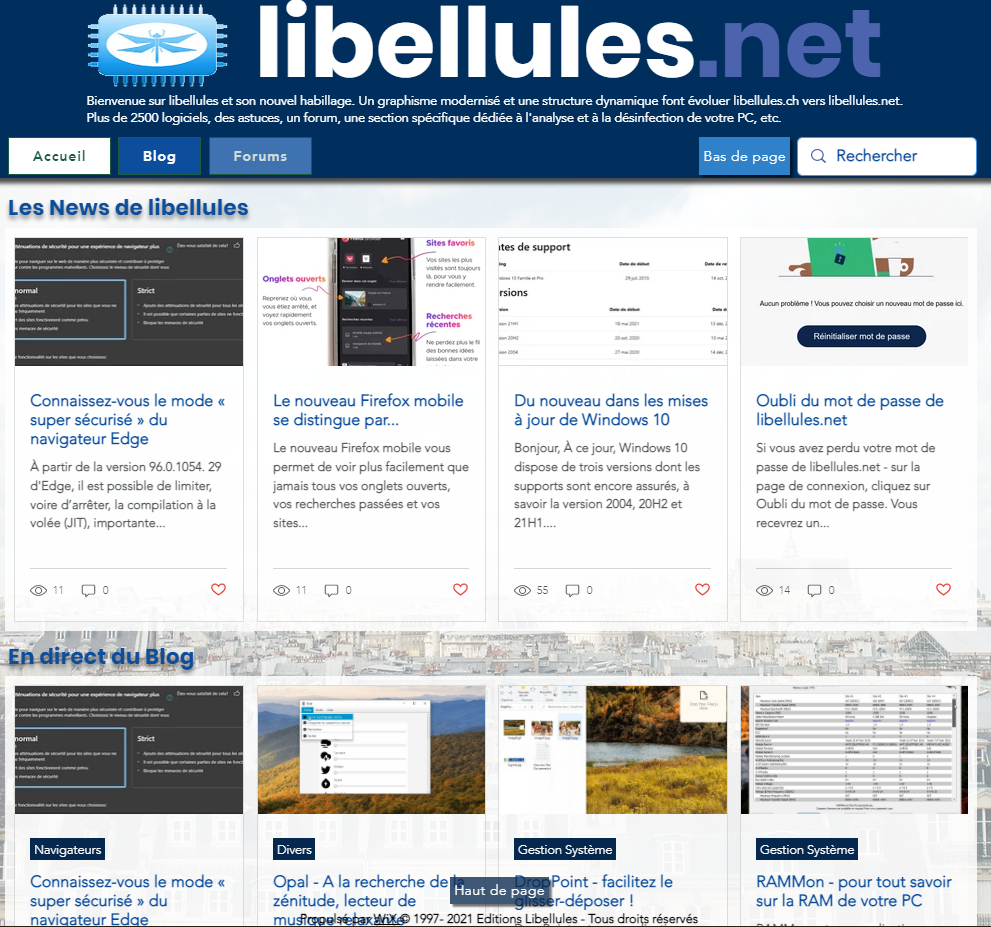
Encore en rodage, je vous remercie d'avance pour votre patience et pour les petits problèmes qui pourraient survenir... Krigou